
The other day I was playing around with some Bureau of Meteorology data for my little patch of the Adelaide Hills (free data — how can I resist?), when I discovered an interesting trend.
Living on a little farm with a small vineyard, I’m rather keen on understanding our local weather trends. Being a scientist, I’m also rather inclined to analyse data.
My first question was given the strong warming trend here and everywhere else, plus ample evidence of changing rainfall patterns in Australia (e.g., see here, here, here, here, here), was it drying out, getting wetter, or was the seasonal pattern of rainfall in my area changing?
I first looked to see if there was any long-term trend in total annual rainfall over time. Luckily, the station records nearest my farm go all the way back to 1890:
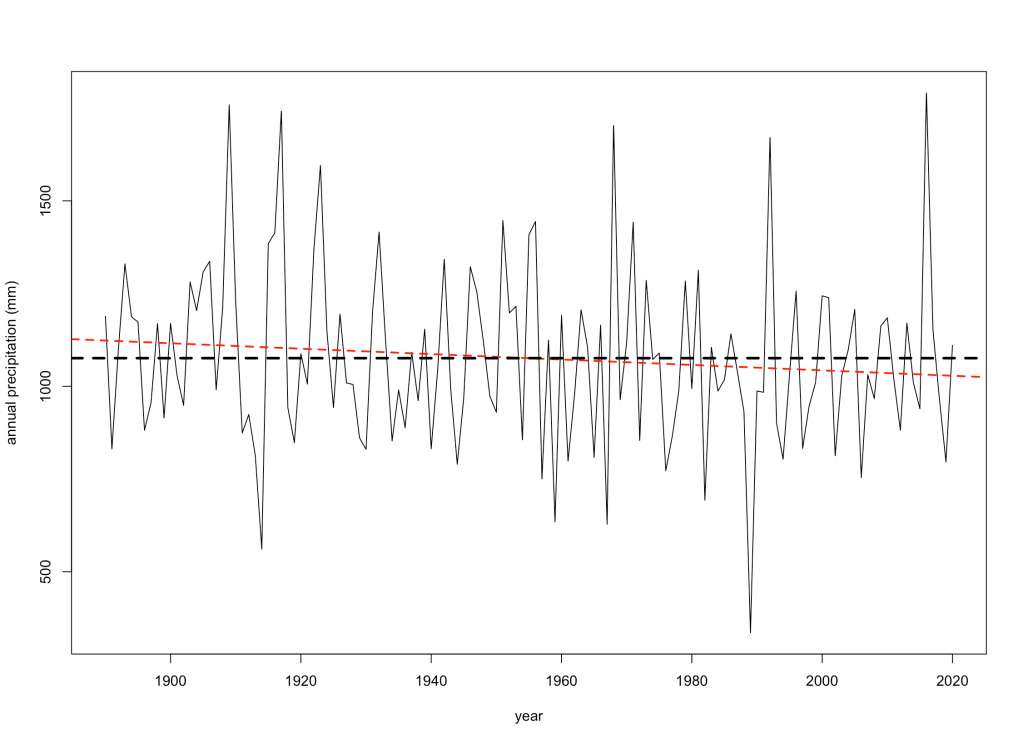
While the red line might suggest a slight decrease since the late 19th Century, it’s no different to an intercept-only model (evidence ratio = 0.84) — no trend.
Here’s the R code to do that analysis (you can download the data here, or provide your own data in the same format):
## IMPORT MONTHLY PRECIPITATION DATA
dat <- read.table("monthlyprecipdata.csv", header=T, sep=",")
## CALCULATE ANNUAL VECTORS
precip.yr.sum <- xtabs(dat$Monthly.Precipitation.Total..millimetres. ~ dat$Year)
precip.yr.sum <- precip.yr.sum[-length(precip.yr.sum)]
year.vec <- as.numeric(names(precip.yr.sum))
## PLOT
plot(year.vec, as.numeric(precip.yr.sum), type="l", pch=19, xlab="year", ylab="annual precipitation (mm)")
fit.yr <- lm(precip.yr.sum ~ year.vec)
abline(fit.yr, lty=2, lwd=2, col="red")
abline(h=mean(as.numeric(precip.yr.sum)),lty=2, lwd=3)
## TEST FOR TREND
# functions
AICc <- function(...) {
models <- list(...)
num.mod <- length(models)
AICcs <- numeric(num.mod)
ns <- numeric(num.mod)
ks <- numeric(num.mod)
AICc.vec <- rep(0,num.mod)
for (i in 1:num.mod) {
if (length(models[[i]]$df.residual) == 0) n <- models[[i]]$dims$N else n <- length(models[[i]]$residuals)
if (length(models[[i]]$df.residual) == 0) k <- sum(models[[i]]$dims$ncol) else k <- (length(models[[i]]$coeff))+1
AICcs[i] <- (-2*logLik(models[[i]])) + ((2*k*n)/(n-k-1))
ns[i] <- n
ks[i] <- k
AICc.vec[i] <- AICcs[i]
}
return(AICc.vec)
}
delta.AIC <- function(x) x - min(x) ## where x is a vector of AIC
weight.AIC <- function(x) (exp(-0.5*x))/sum(exp(-0.5*x)) ## Where x is a vector of dAIC
ch.dev <- function(x) ((( as.numeric(x$null.deviance) - as.numeric(x$deviance) )/ as.numeric(x$null.deviance))*100) ## % change in deviance, where x is glm object
linreg.ER <- function(x,y) { # where x and y are vectors of the same length; calls AICc, delta.AIC, weight.AIC functions
fit.full <- lm(y ~ x); fit.null <- lm(y ~ 1)
AIC.vec <- c(AICc(fit.full),AICc(fit.null))
dAIC.vec <- delta.AIC(AIC.vec); wAIC.vec <- weight.AIC(dAIC.vec)
ER <- wAIC.vec[1]/wAIC.vec[2]
r.sq.adj <- as.numeric(summary(fit.full)[9])
return(c(ER,r.sq.adj))
}
linreg.ER(year.vec, as.numeric(precip.yr.sum))
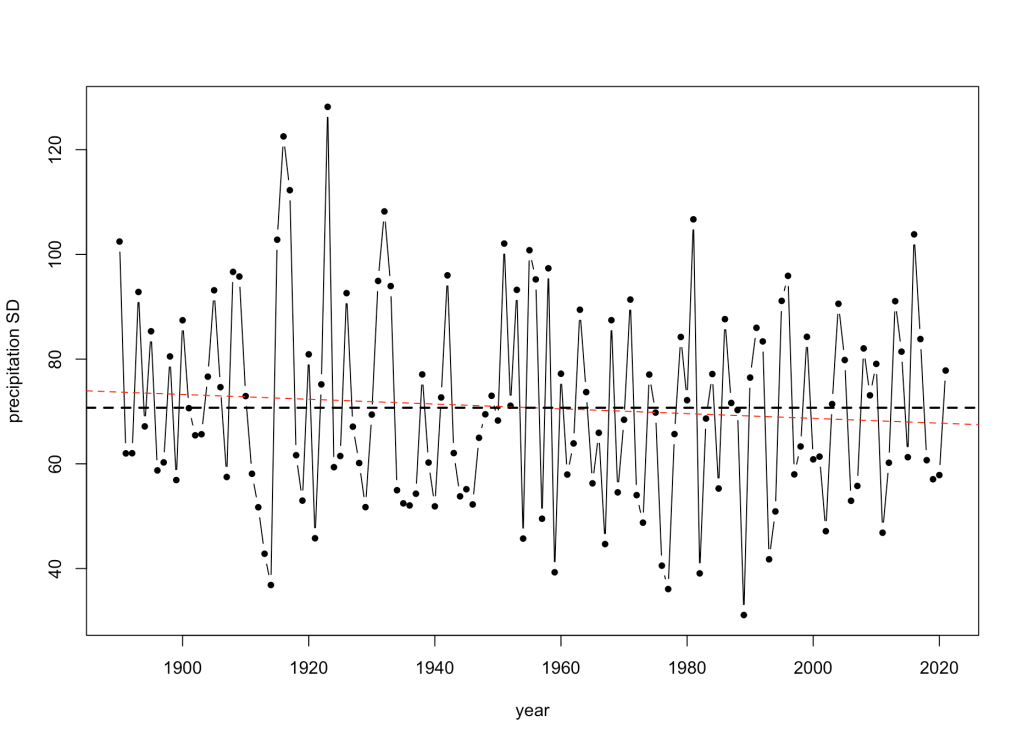
Ok, what about seasonal variability? Plotting the annual standard deviation of monthly total rainfall, we still see no trend:
year.vec <- as.numeric(unique(dat$Year))
precip.sd <- precip.cv <- precip.mn <- rep(0,length(year.vec))
for (y in 1:length(year.vec)) {
dat.sub <- subset(dat, Year == year.vec[y])
precip.sd[y] <- sd(dat.sub$Monthly.Precipitation.Total..millimetres.)
precip.mn[y] <- mean(dat.sub$Monthly.Precipitation.Total..millimetres.)
precip.cv[y] <- precip.sd[y]/precip.mn[y]
}
plot(year.vec, precip.sd, xlab="year", ylab="precipitation SD", pch=19, cex=0.7, type="b")
fit.precipsd <- lm(precip.sd ~ year.vec)
abline(fit.precipsd, lty=2, col="red")
abline(h=mean(precip.sd), lty=2, lwd=2)
linreg.ER(year.vec, precip.sd)
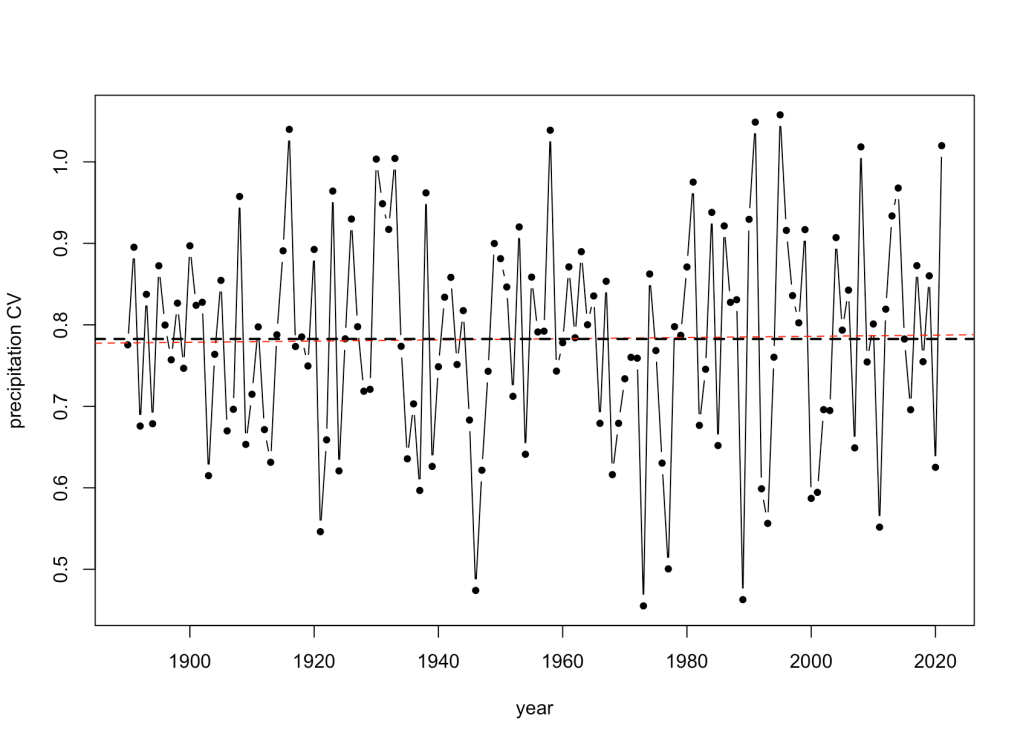
Or, coefficient of variation? No trend either:
plot(year.vec, precip.cv, xlab="year", ylab="precipitation CV", pch=19, cex=0.7, type="b")
fit.precipcv <- lm(precip.cv ~ year.vec)
abline(fit.precipcv, lty=2, col="red")
abline(h=mean(precip.cv), lty=2, lwd=2)
linreg.ER(year.vec, precip.cv)
Ok. Let’s approach this another way. What if the frequency of ‘extreme’ years (either extremely dry, or extremely wet) is changing?
The first thing is defining what ‘extreme’ means; unfortunately, there’s no easy rule to follow. Generally speaking, we identify ‘extreme’ events relative to the distribution. For example, any event that is greater than some multiple of standard deviations above or below the mean might qualify. The question is, what is that multiple?
The multiple to choose is generally a trade-off between enough extreme events to test for a trend (i.e., a multiple of standard deviation that is too high will yield few extreme events), and what we consider to be ‘extreme’. In my particular case, anything above 1 standard deviation in annual totals yields enough extreme events to test for trends:
n.sds <- 1
yearly.sd <- sd(as.numeric(precip.yr.sum))
yearly.mn <- mean(as.numeric(precip.yr.sum))
upp.lim <- yearly.mn + (n.sds*yearly.sd)
low.lim <- yearly.mn - (n.sds*yearly.sd)
times.upp <- which(as.numeric(precip.yr.sum) > upp.lim)
times.low <- which(as.numeric(precip.yr.sum) < low.lim)
time.diffs.upp <- diff(times.upp)
time.diffs.low <- diff(times.low)
plot(year.vec[times.upp[-1]], time.diffs.upp, pch=19, xlab="year", ylab="years between high extremes")
times.upp.fit <- lm(time.diffs.upp ~ year.vec[times.upp[-1]])
abline(times.upp.fit, lty=2, col="red")
linreg.ER(year.vec[times.upp[-1]], time.diffs.upp)
This gives the change in interval between extremely wet years over the time:
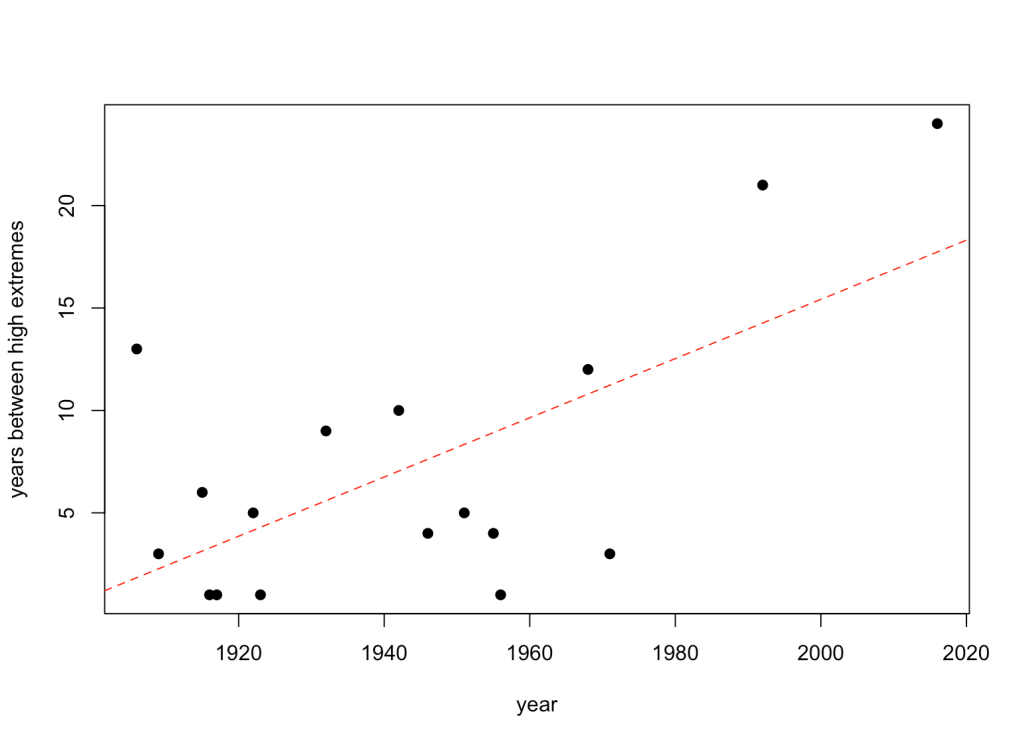
Ok! This seems to suggest evidence for an increasing interval between extremely wet events (evidence ratio = 22; R2 = 0.38). How about extreme dry years?:
plot(year.vec[times.low[-1]], time.diffs.low, pch=19, xlab="year", ylab="years between low extremes")
times.low.fit <- lm(time.diffs.low ~ year.vec[times.low[-1]])
abline(times.low.fit, lty=2, col="red")
linreg.ER(year.vec[times.low[-1]], time.diffs.low)
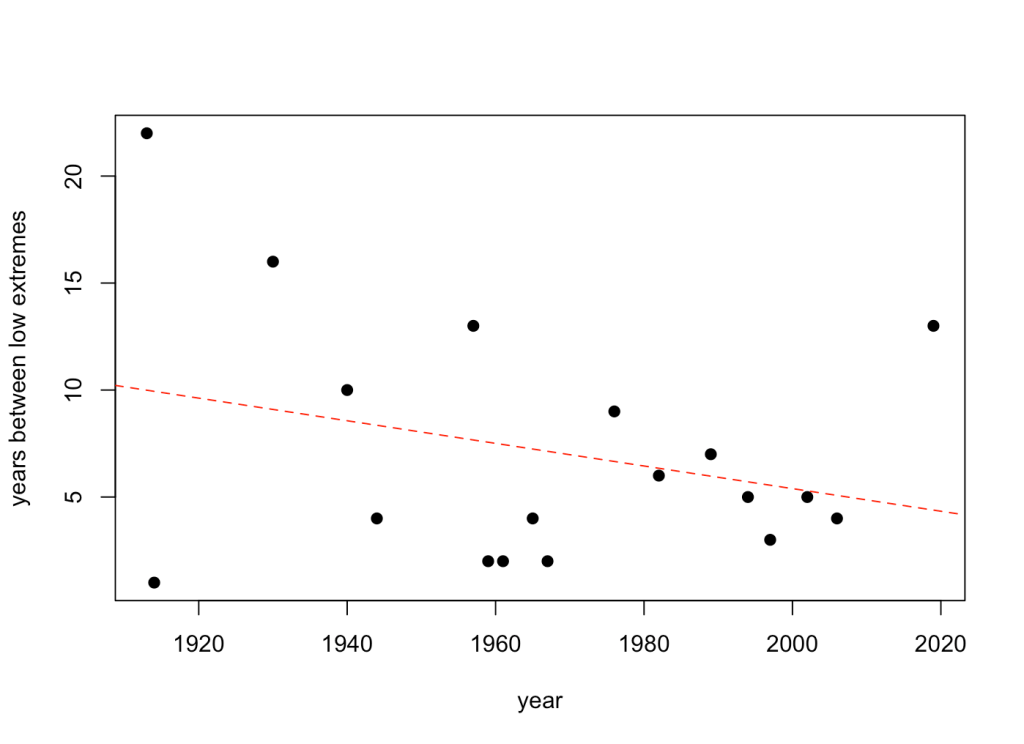
Hmmm. While the trend seems to suggest a declining interval between extremely dry years, there’s no statistical evidence to support the trend (evidence ratio = 0.51).
Nonetheless, it does appear to match the long-term trends in south-eastern Australia showing that our big, wet years are becoming less frequent. These have pretty profound implications for everything from human water supply to bushfire risk.
Keen to hear any thoughts about how to progress this type of analysis. Try it on your own region’s datasets too.





Love this one
LikeLike