Back in April I blogged about an idea I had to provide a more discipline-, gender-, and career stage-balanced way of ranking researchers using citation data.
Most of you are of course aware of the ubiquitous h-index, and its experience-corrected variant, the m-quotient (h-index ÷ years publishing), but I expect that you haven’t heard of the battery of other citation-based indices on offer that attempt to correct various flaws in the h-index. While many of them are major improvements, almost no one uses them.
Why aren’t they used? Most likely because they aren’t easy to calculate, or require trawling through both open-access and/or subscription-based databases to get the information necessary to calculate them.
Hence, the h-index still rules, despite its many flaws, like under-emphasising a researcher’s entire body of work, gender biases, and weighting towards people who have been at it longer. The h-index is also provided free of charge by Google Scholar, so it’s the easiest metric to default to.
So, how does one correct for at least some of these biases while still being able to calculate an index quickly? I think we have the answer.
Since that blog post back in April, a team of seven scientists and I from eight different science disciplines (archaeology, chemistry, ecology, evolution & development, geology, microbiology, ophthalmology, and palaeontology) refined the technique I reported back then, and have submitted a paper describing how what we call the ‘ε-index’ (epsilon index) performs.
While the paper is still in review, we have published a pre-print of the article, as well as provided the original R code.

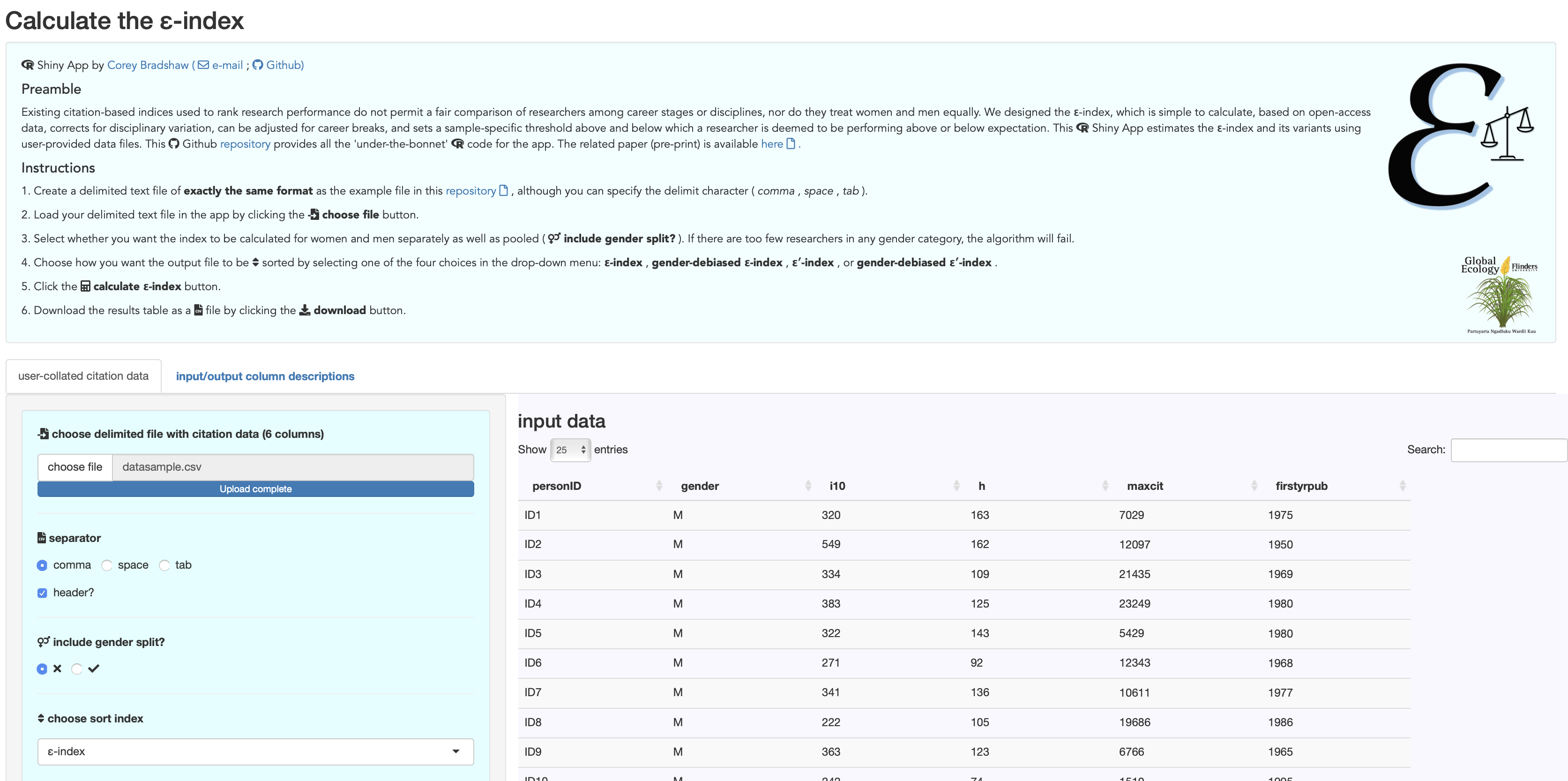
But in the spirit of making the index as easy as possible to calculate, I’ve also finally dived into the murky waters of app development using RStudio’s Shiny package, and its app-hosting website, shinyapps.io.
I’ve wanted to learn Shiny for a some time, and the ε-index provided the perfect opportunity to do so.
Armed with easily obtainable data (e.g., from Google Scholar) for a list of any researchers you might wish to compare, the new Shiny app calculates the ε-index (and its variants) automatically for you. You can then download the results to a text file for use elsewhere.
You can access and use the ε-index app here: cjabradshaw.shinyapps.io/epsilonIndex.
I’ve provided an easy-to-use protocol for using the app, but it’s pretty straight-forward even without reading the protocol. You’ll of course need to format the necessary citation data (i10, h-index, number of citations of most highly cited paper, years since publishing first peer-reviewed paper) in a particular way (described here), but then the app does everything else for you.
I had also developed a Google Scholar subroutine that ‘scrapes’ the necessary data from Google directly (to which you then can pass the resultant file to the ε-index app), but it only works from a user’s machine. This is because third-party apps aren’t permitted to scrub data from Google Scholar (it violates their terms of service). I spent far too long coding a Google Authenticator that works well, but is blocked by Google all the same. Sigh.
Still, if you want to use the Google Scholar subroutine scraper from your own machine, all the code is available here.
I plan to use this approach from now on when doing any preliminary rankings of job applicants, promotion seekers, grant applicants, etc. I hope many other people do too.
I’ll of course signal when the paper is finally published.





[…] this time I’ve strayed from my recent bibliometric musings and developed something that’s more compatible with the core of my main research and […]
LikeLike
[…] week I reported that I had finally delved into the world of R Shiny to create an app that calculates relative […]
LikeLike
It would be cool to have some incoporation of ‘first-name’ publications into the index. In my field, it is mostly first name pubs that are counted for ECRs.
Also in get.profiledat.func code, profilelist should be profile.list?
maxcits[r] <- get_publications(as.character(profileslist[[r]]$id))$cites[1]
Y1s[r] <- get_oldest_article(profileslist[[r]]$id)
LikeLike
Thanks for the typo spot. I’ve fixed that now on Github. I guess there are all sorts of mods I can make to this down the track, including the one you mention.
LikeLike