originally published in Brave Minds, Flinders University’s research-news publication (text by David Sly)
Clues to understanding human interactions with global ecosystems already exist. The challenge is to read them more accurately so we can design the best path forward for a world beset by species extinctions and the repercussions of global warming.

This is the puzzle being solved by Professor Corey Bradshaw, head of the Global Ecology Lab at Flinders University. By developing complex computer modelling and steering a vast international cohort of collaborators, he is developing research that can influence environmental policy — from reconstructing the past to revealing insights of the future.
As an ecologist, he aims both to reconstruct and project how ecosystems adapt, how they are maintained, and how they change. Human intervention is pivotal to this understanding, so Professor Bradshaw casts his gaze back to when humans first entered a landscape – and this has helped construct an entirely fresh view of how Aboriginal people first came to Australia, up to 75,000 years ago.
Two recent papers he co-authored — ‘Stochastic models support rapid peopling of Late Pleistocene Sahul‘, published in Nature Communications, and ‘Landscape rules predict optimal super-highways for the first peopling of Sahul‘ published in Nature Human Behaviour — showed where, how and when Indigenous Australians first settled in Sahul, which is the combined mega-continent that joined Australia with New Guinea in the Pleistocene era, when sea levels were lower than today.
Professor Bradshaw and colleagues identified and tested more than 125 billion possible pathways using rigorous computational analysis in the largest movement-simulation project ever attempted, with the pathways compared to the oldest known archaeological sites as a means of distinguishing the most likely routes.
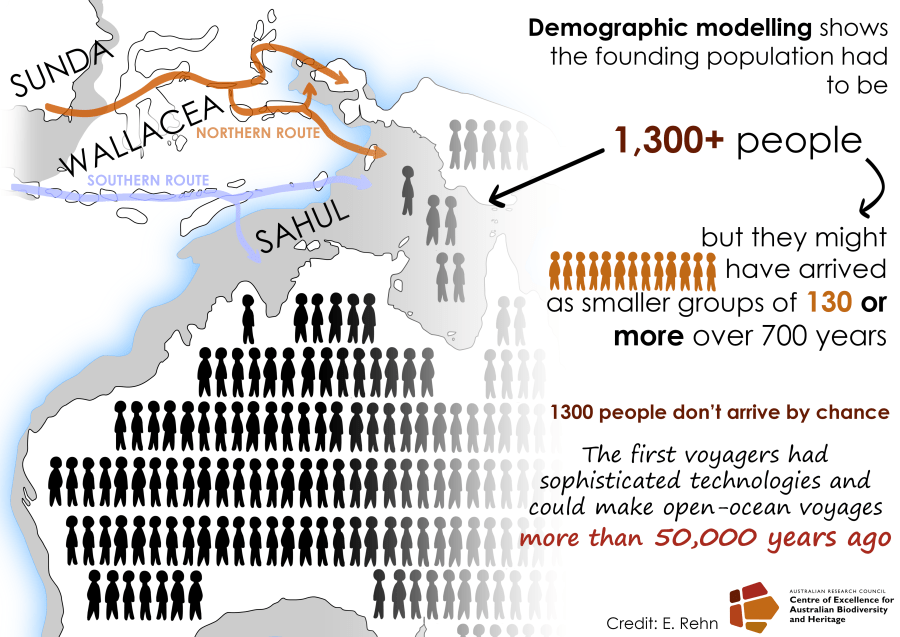
The study revealed that the first Indigenous people not only survived but thrived in harsh environments, providing further evidence of the capacity and resilience of the ancestors of Indigenous people, and suggests large, well-organised groups were able to navigate tough terrain.
Read the rest of this entry »






